Solutions
Knowledge Synthesis
Transform unstructured enterprise data into actionable intelligence with RAG pipelines, knowledge graphs, and AI-powered retrieval.
Transform unstructured enterprise data into actionable intelligence with RAG pipelines, knowledge graphs, and AI-powered retrieval.
Documents, databases, email, contracts, tickets, people, events — every source your business runs on, woven into one connected substrate. Agents don't guess; they reach into it, follow the connections, and ground every answer in what's actually true.
Our RAG pipelines connect language models directly to your enterprise knowledge base, ensuring every response is grounded in verified, up-to-date information. The result: accurate, trustworthy AI outputs your team can rely on.

Our knowledge graph technology maps relationships across your entire data ecosystem, surfacing insights that flat databases and simple search can never reveal. Understand context, dependencies, and patterns at enterprise scale.
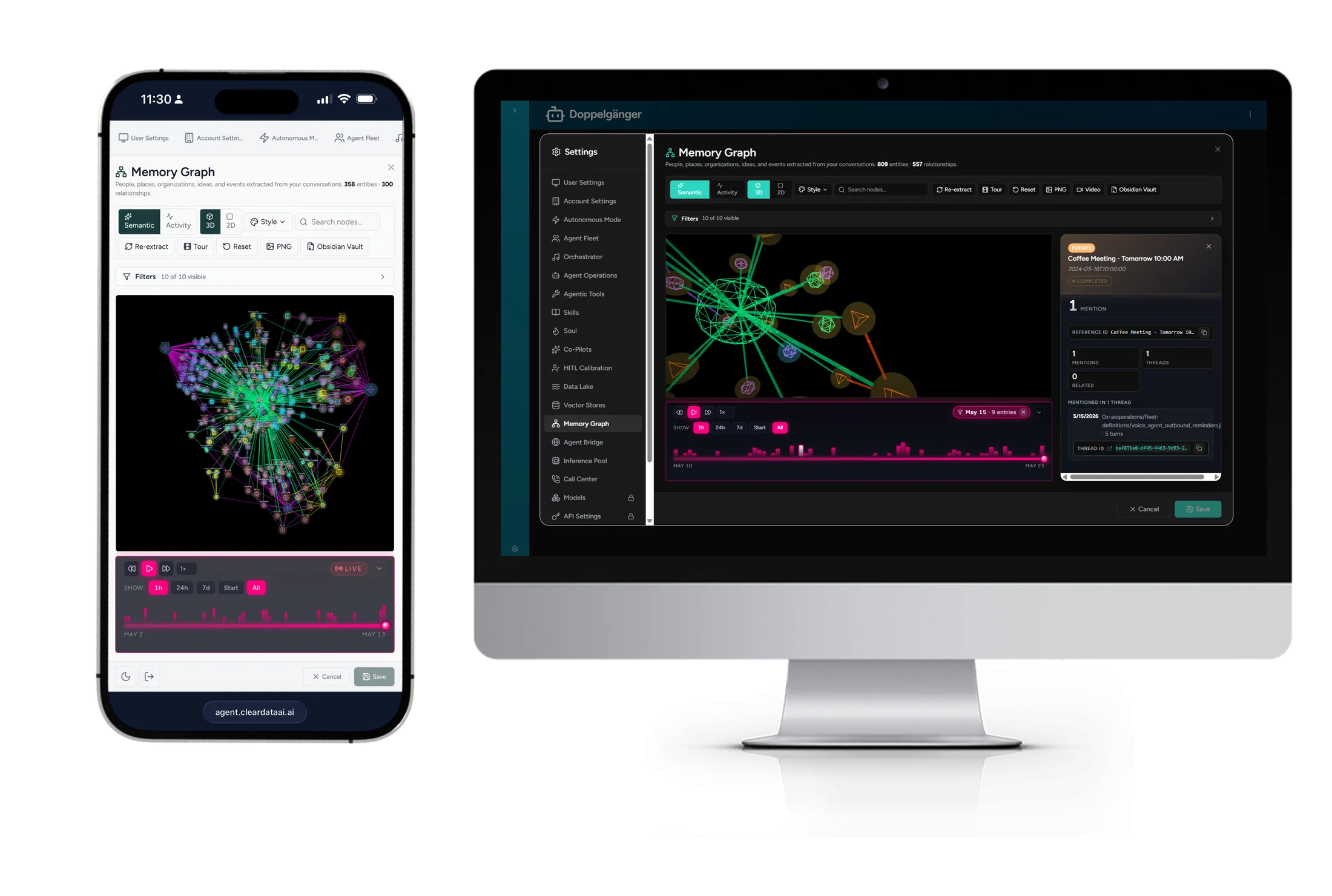
Information silos are the enemy of good decision-making. Our AI synthesizes knowledge from every department, system, and document format — creating a unified intelligence layer that makes institutional knowledge accessible to everyone.
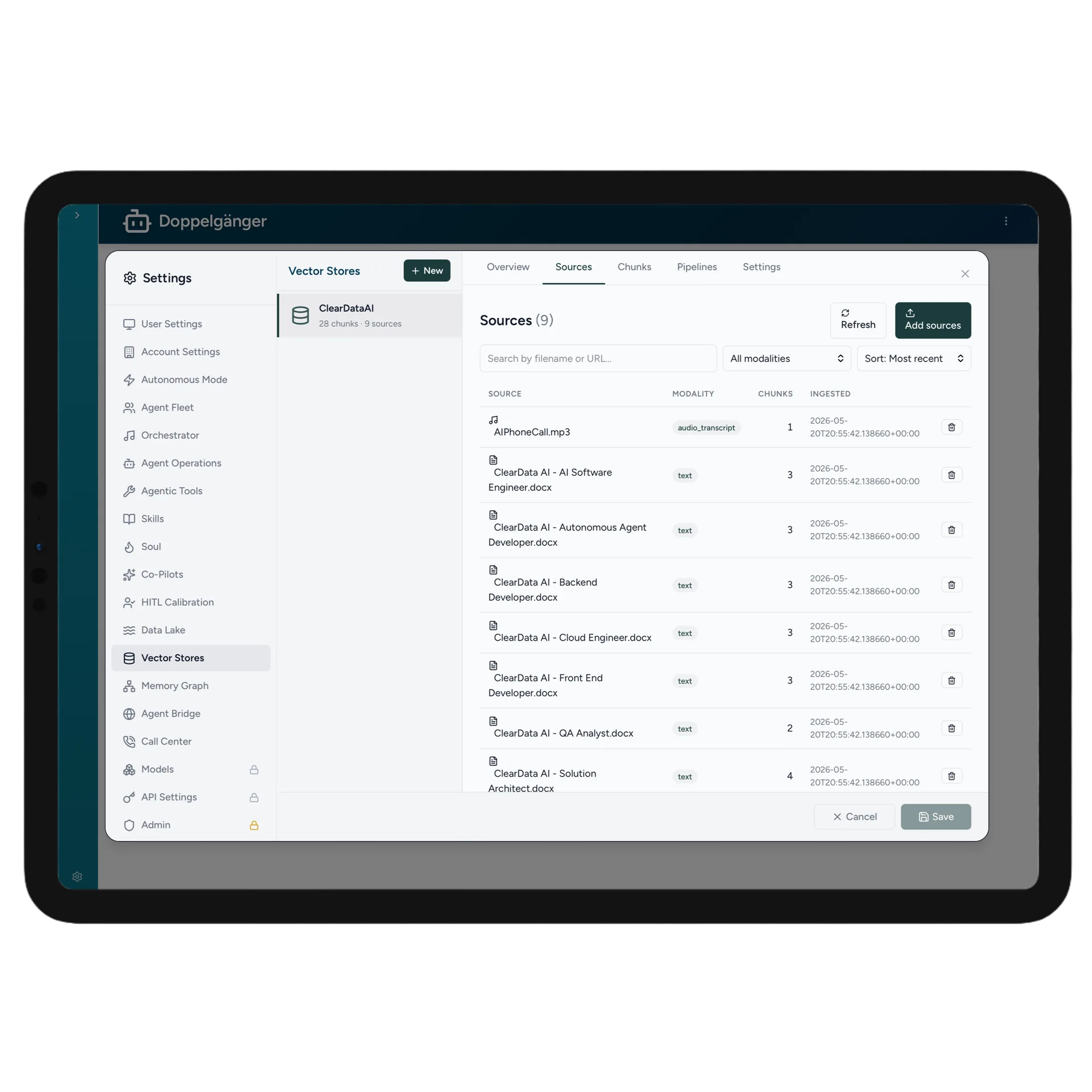
Before knowledge can be synthesized, it has to be broken down intelligently and represented as meaning — not just text. Every source is split into context-rich chunks and embedded as vectors, so retrieval finds what's relevant by meaning and cites the exact passage it came from.
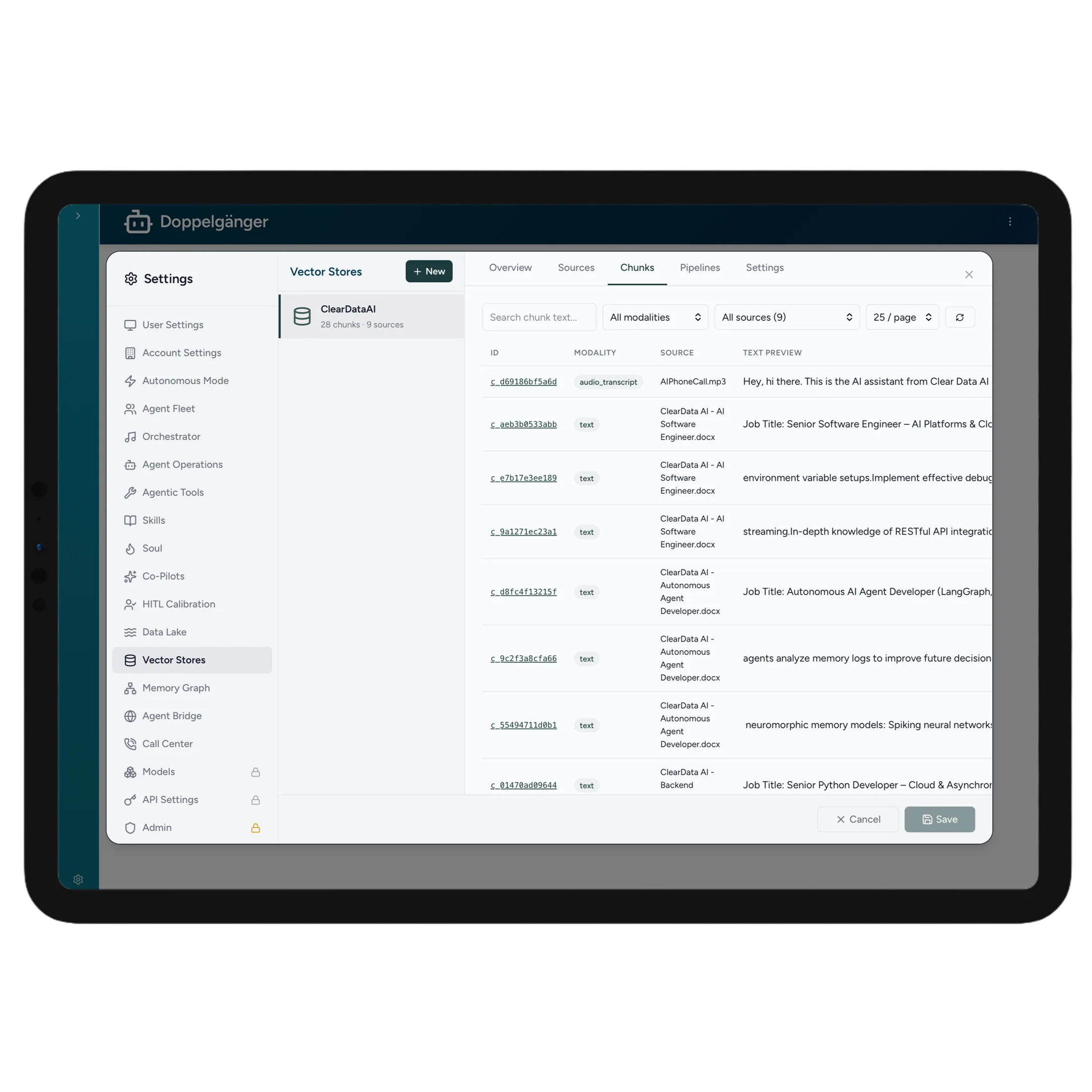
Documents, transcripts, and code are segmented into right-sized chunks that preserve context — each one linked back to its exact source for verifiable, cited answers.
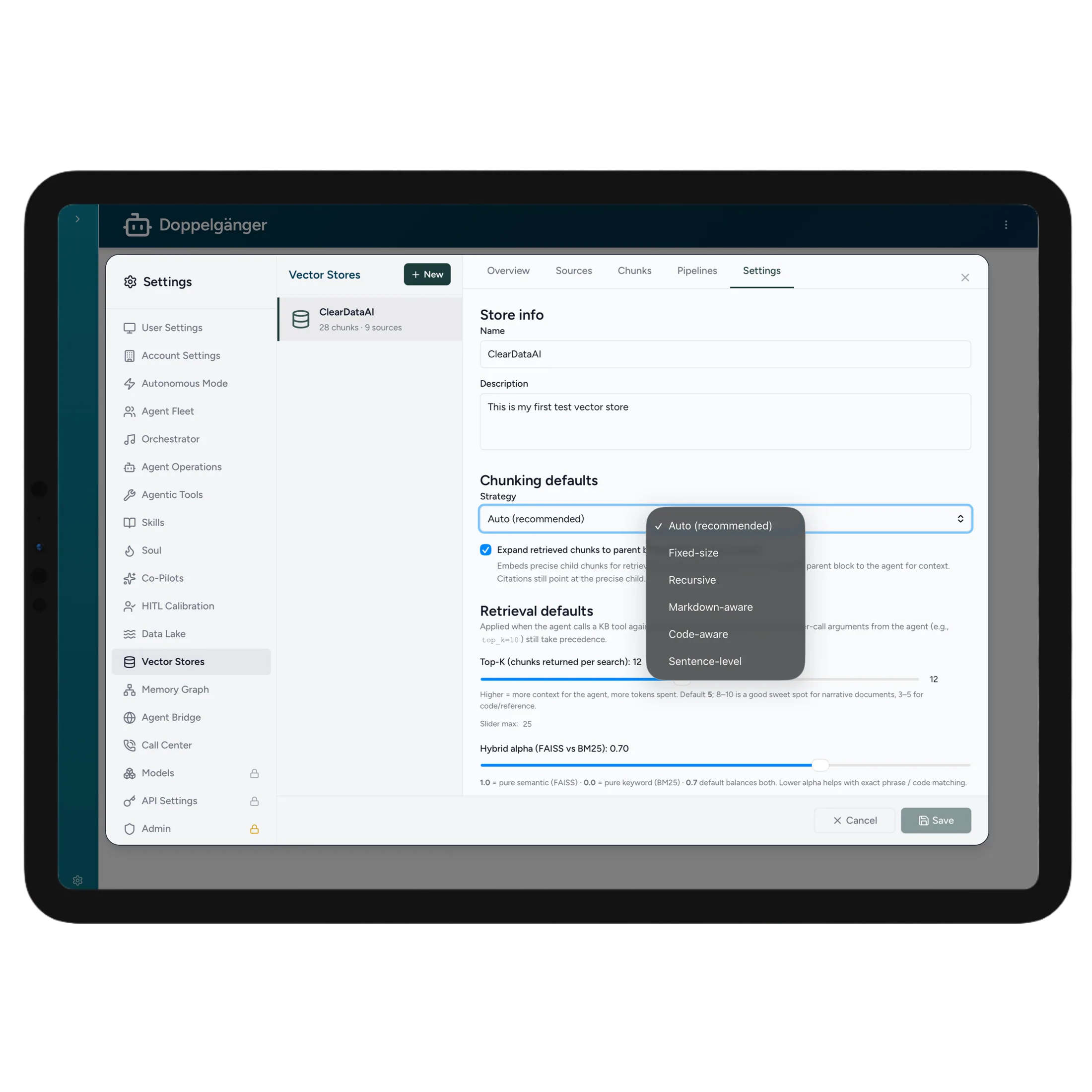
Pick the chunking strategy that fits each source and embed it into a vector store — then blend semantic and keyword search so the most relevant passages surface every time.
See how our knowledge management solutions can transform the way your team accesses and uses information.
Get Started